
Opsgenie est une plateforme de gestion des incidents moderne qui offre de la flexibilité aux équipes DevOps dans la gestion de leurs activités, qu’elles soient planifiées ou non. Valiantys propose une offre Cloud qui a séduit de très nombreux clients. Nous avions besoin d’un outil nous offrant un maximum de réactivité aux incidents affectant nos environnements clients. Opsgenie nous offre la possibilité de recevoir nos alertes de façon centralisée, mais également de filtrer celles qui nécessitent une attention immédiate.
Opsgenie permet à Valiantys de mieux gérer les alertes pour son Support client
Le diagramme ci-dessous détaille notre workflow actuel chez Valiantys.
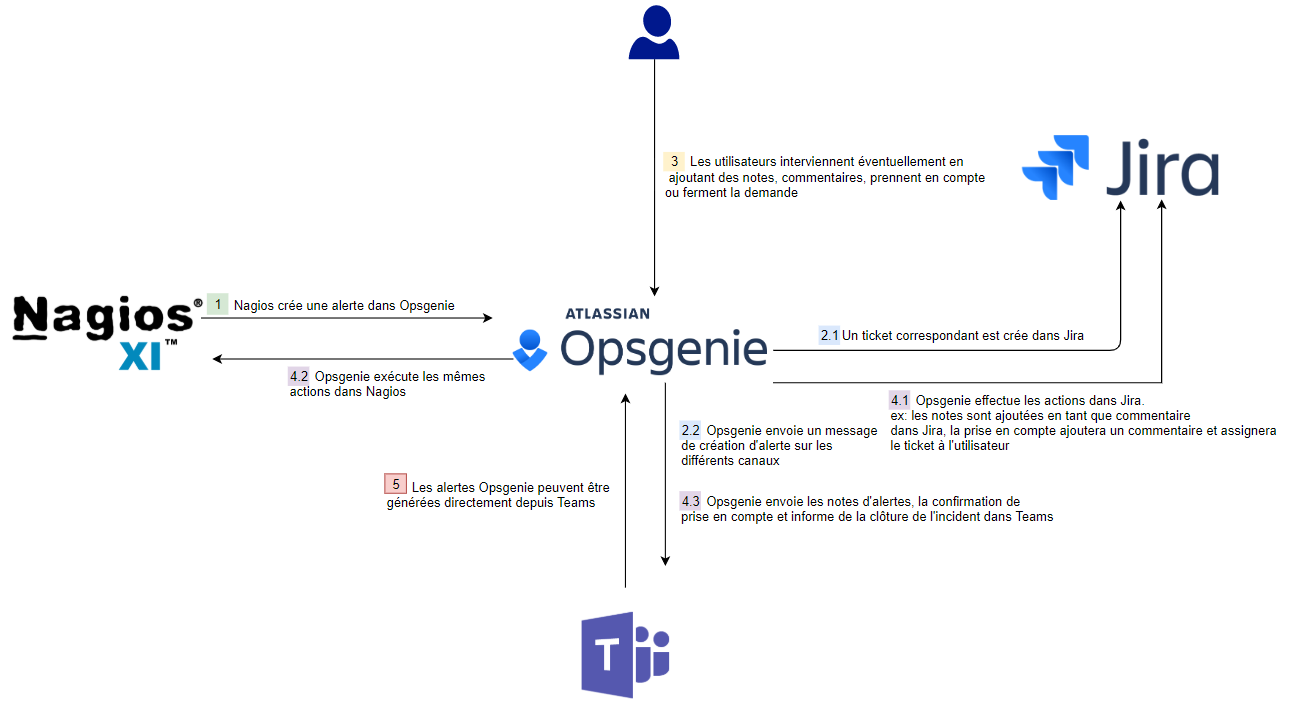
- Nous utilisons Nagios pour le monitoring de nos serveurs. Nous l’avons intégré à Opsgenie via les intégrations fournies nativement. Le cycle démarre quand Nagios détecte une alerte et l’envoie à Opsgenie.
- Dès que l’alerte arrive sur Opsgenie, elle créée automatiquement une demande dans notre Jira Service Desk. Ceci est très important pour nous car cela nous permet de bénéficier des fonctionnalités de Jira : les alertes sont visibles par du personnel non technique et du reporting peut être mis en place. Opsgenie envoie également l’alerte sur Microsoft Teams (ou d’autres outils collaboratifs, il existe de nombreuses intégrations par défaut).
- Depuis l’interface d’Opsgenie, les utilisateurs peuvent prendre en compte une alerte, la commenter ou la clôturer.
- Les actions effectuées sur l’alerte sont automatiquement poussées dans Jira et Microsoft Teams. Les notes sont ajoutées en tant que commentaires sur les demandes Jira Service Desk créées depuis les alertes. Prendre en compte une alerte attribuera la demande Jira Service Desk à l’agent qui traitera la demande. Les alertes sont également synchronisées entre Opsgenie et Nagios. Cela est notamment utile lorsque nous avons de fausses alertes que nous voulons clôturer dans Nagios.
- Toutes ces actions peuvent être effectuées directement depuis Microsoft Teams.
Notre expérience de configuration d’Opsgenie pour Valiantys nous permet de partager une liste non exhaustive des fonctionnalités qui nous ont simplifié la vie. Je pense sincèrement que ce sont ces fonctionnalités qui font d’Opsgenie un outil de gestion d’alertes idéal.
Intégrations disponibles
Comme vous avez pu le constater dans le paragraphe ci-dessus, les intégrations à Jira, Nagios et Microsoft Teams sont disponibles par défaut et ne demandent qu’à être configurées. Il en est de même avec de très nombreux outils de monitoring, de chat ou de plateformes Cloud. Dans le cas où votre outil ne disposerait pas d’une intégration native, vous pouvez utiliser l’intégration via mail ou webhook.
Voici quelques intégrations disponibles nativement :

Actions sur les alertes
Recevoir trop d’alertes quand vous n’en êtes pas le responsable peut être perturbant et vous faire perdre du temps. Opsgenie dispose d’un moteur de règles permettant de filtrer les alertes et de ne les envoyer qu’aux bonnes personnes sur le bon canal, au bon moment. Vous n’aurez peut être pas envie de recevoir des alertes SMS à minuit (ou peut être le voudrez-vous !). Qui plus est, les alertes peuvent être enrichies de nombreux détails provenant de vos outils de monitoring.
Enfin, les alertes seront plus simples à traiter si elles sont générées dans un contexte adapté. Le fait que les utilisateurs puissent commenter, attacher des logs ou des procédures aux alertes simplifie leur traitement et facilite la prise de décision. Si les alertes doivent être escaladées au niveau supérieur ou transférées à un autre ingénieur support, toutes les informations seront tracées dans l’alerte.
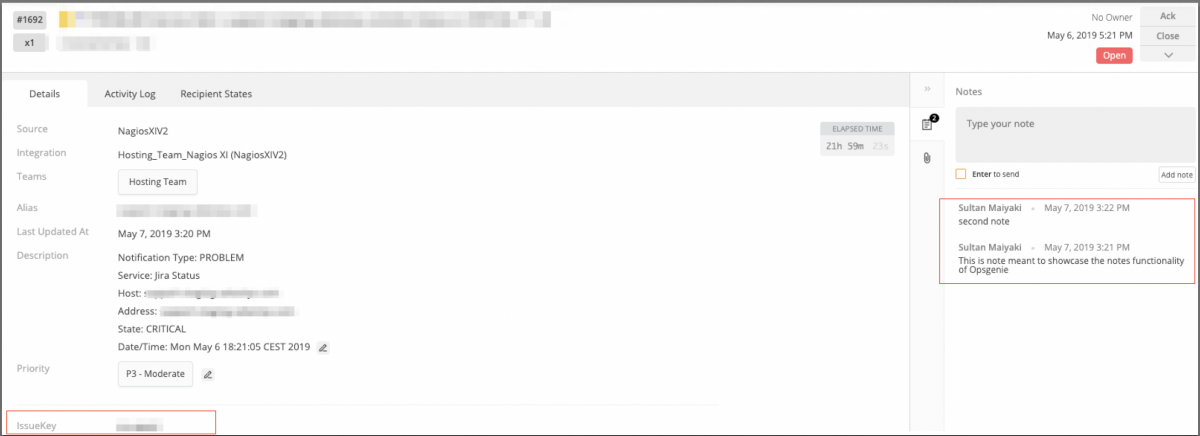

Escalades
Opsgenie permet de créer des règles d’escalades afin d’alerter d’autres personnes lorsque les alertes ne sont pas prises en compte ou traitées dans un délai pré-déterminé. Les escalades automatiques permettent de s’assurer que les SLA sont respectés et que les clients subissent des temps d’indisponibilité réduits au minimum.
Pour créer un escalade, dirigez-vous vers l’équipe concernée et visitez la page “escalation”. Cela vous donnera accès à une page permettant de définir vos règles. Voici un exemple de règle.
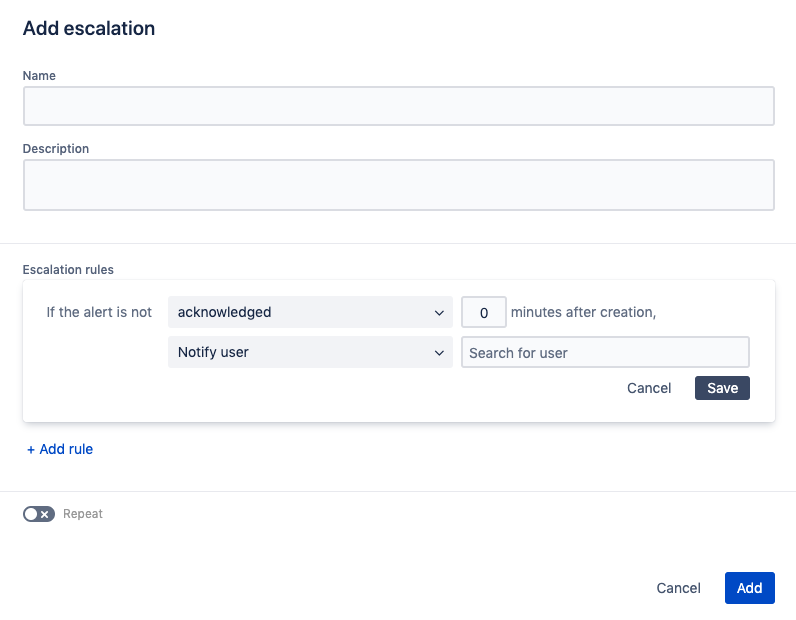
Chez Valiantys nous avons défini trois règles basiques d’escalade. La première permet de notifier le responsable d’équipe lorsqu’une alerte n’a pas été résolue dans les 20mn. La seconde informe les personnes d’astreinte, durant un week-end par exemple, lorsqu’une alerte n’a pas été résolue dans les 20mn. Et la troisième permet d’escalader à la personne d’astreinte suivante sur la liste si l’alerte n’a pas été prise en compte dans les 5mn puis de notifier l’ensemble des membres de l’équipe au bout de 10mn sans action.
Politiques
Les politiques sont assez proches des règles d’escalade. La différence majeure réside dans le fait que l’on peut ajuster le contenu et le destinataire des alertes, ainsi que leur cycle de vie, a contrario des politiques. Vous pouvez par exemple utiliser les politiques lorsque vous devez gérer des opérations planifiées affectant vos ressources. Dans un tel scenario, vous pouvez créer une politique qui désactivera les notifications liées à ces alertes. Un autre exemple est concerne les politiques que nous utilisons lorsque nous gérons des instances temporaires pour nos clients dans le cadre d’un Proof of Concept. Nous créons une politique particulière afin de gérer ces instances différemment de nos instances de production ne nécessitant pas la même réactivité.
Incidents
Les incidents sont une catégorie spécifique d’alertes qui doivent être considérés en priorité, soit à cause de leur récurrence, soit car il y a une interruption de service. Pour les incidents, vous voudrez informer toutes les parties prenantes impliquées dans les étapes d’investigation. A la résolution de l’incident, vous aurez rassemblé beaucoup d’informations et de communications qui pourront vous servir à rédiger un article sur le sujet dans une base de connaissances. Autre fonctionnalité intéressante, vous pouvez démarrer une visio-conférence directement depuis un incident avec l’ensemble des parties prenantes.
Reporting
Le fait que l’ensemble des alertes soient centralisées dans Opsgenie permet d’obtenir une vue d’ensemble de l’état de santé de votre infrastructure. L’outil offre une vue centralisée pour les Dev et les Ops selon les critères qui leur importent. Chez Valiantys, nous sommes en capacité de prendre des décisions qui affectent notre infrastructure ou l’équipe de support à partir des données fournies par Opsgenie. Nous pouvons mesurer comment les membres de l’équipes répondent aux incidents, l’âge moyen des incidents ou encore identifier les services qui en génèrent le plus.
Les bénéfices d’Opsgenie pour Valiantys
Depuis que nous avons commencé à utiliser Opsgenie en tant que système de gestion des alertes, nous avons amélioré le suivi des alertes pour nos centaines de plateformes client. Nous pouvons gérer nos activités de maintenance plus sereinement et les incidents sont résolus plus rapidement, plus efficacement et avec une meilleure traçabilité. Opsgenie dispose de nombreuses fonctionnalités. Celles présentées dans cet article ne sont qu’un échantillon de ce qui existe et sont celles que nous avons trouvées les plus pertinentes pour nos propres besoins. Il est prévu d’étendre notre usage du produit pour continuer à optimiser notre gestion des incidents.
Notre expérience vous inspire ? Améliorez vous aussi vos performances ITSM à l’aide d’Opsgenie.
En savoir plus


