
When it comes to incident management, you need a system that allows for maximum flexibility. That’s especially important when you’re managing Atlassian services for a wide range of customers, like we do here at Valiantys. Meet Opsgenie: a modern, cutting-edge platform that allows our team to respond more efficiently to the incidents that are affecting our customers’ environments – planned or unplanned. We can even filter out the alerts that need our urgent attention. Now there’s a handy tool!
Valiantys Customer Support via Opsgenie
With Opsgenie, our workflow looks like this:

Opsgenie comes with a number of plug-and-play integrations. We use Nagios XI to monitor our servers, so all we had to do was connect the two. Whenever Nagios detects a failure, it sends an alert to Opsgenie.
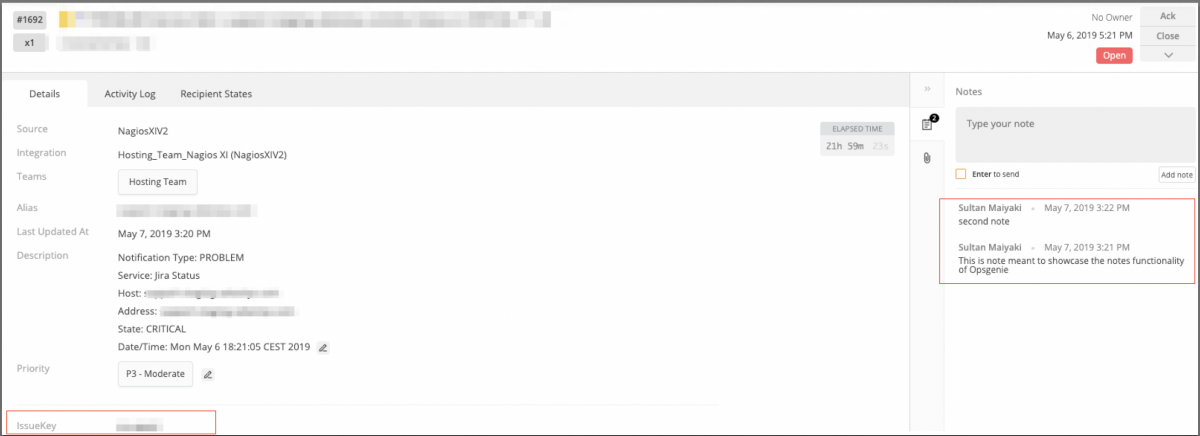
As soon as the alert hits Opsgenie, Jira automatically creates an issue for it. This is a great feature, because it means staff members throughout the company can keep an eye on things. That wider access also makes it easier to create reports and dashboards from the data involved. Opsgenie also sends the alert to your collaboration tool of choice, like Teams.
Once the alert is visible in the Opsgenie UI or in Teams, users can choose from a number of actions like acknowledging the alert, adding a note, or closing the issue. To keep things streamlined, those actions are reflected in Jira and Teams as well.
Any notes will be added as comments to the corresponding Jira issue, and acknowledging an alert automatically assigns the Jira issue to that user.
We also made sure to sync all actions on Opsgenie alerts with our Nagios servers, in case we need to deal with false alerts and want to automatically close the alert in Nagios.
And the best part? All of the above can be done directly from Teams!
Available integrations
As mentioned before, Opsgenie comes with a number of really cool default integrations to Jira, Nagios and Teams, as well as to almost all known automations systems, collaboration tools, and other cloud platforms. Use them wisely, and they will make your life infinitely easier. All you need to do is configure them, and you’re good to go!
And just in case direct integration with your tool is unavailable, you can leverage the built-in email and webhook services to get the same results. Below are some examples of the available integrations:

Actionable alerts
Alerts are disruptive for a reason, but dealing with too many of them can take up a big chunk of your time – especially when they’re about events that you’re not even involved in. Any good incident management tool will enable users to filter alerts, and Opsgenie is no exception. Besides configuring the proper user or channel for each type of alert, users can also tweak alert timing. After all, if you don’t offer round-the-clock support, you might not want to receive alerts at midnight…
Adding the right context will make it even easier to act on alerts, so Opsgenie enables users to add monitoring details like user-defined properties, notes, logs and runbooks. That way, if the incident is escalated or transferred to another engineer, the other party will have all the information they need to resolve it right at their fingertips.

Escalations
The escalations feature lets us nudge stakeholders when they haven’t acknowledged or acted on an alert within a specific time period. That way, we can make sure any issues cause only minimal disruption for our customers.
To create an escalation, simply head to the relevant team and visit the escalation page. This will pull up a form that allows you to add specific rules:
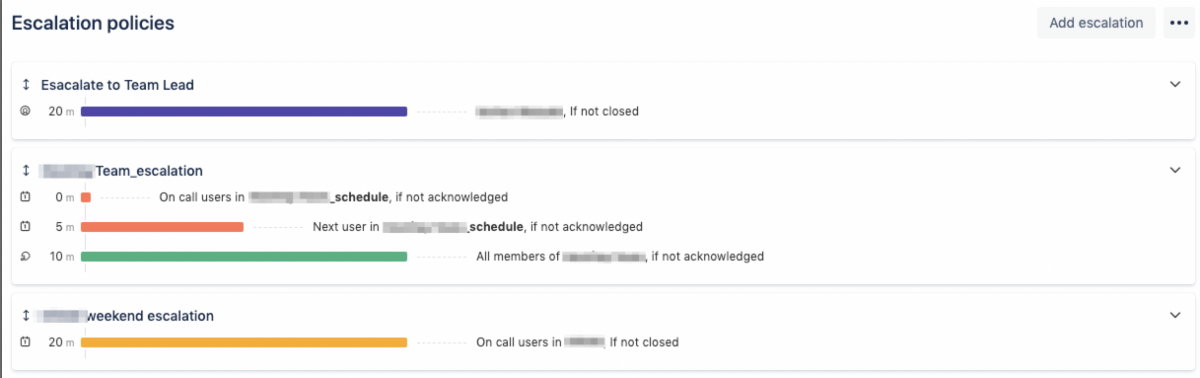
At Valiantys, we work with 3 basic escalation rules. First of all, team leads are notified whenever an alert has been marked as unresolved for 20 minutes. Secondly, whenever an alert is not acknowledged within five minutes, the system will notify the next user on call. (If it takes more than 10 minutes, the whole team is notified.) Finally, if alerts remain unresolved for more than 20 minutes on a weekend day, any staff members on call are notified as well.
Policies
Policies are a set of rules through which users can manage the content and recipients of an alert, as well as the life cycle of alerts and notifications. The major difference between policies and escalations is that policies enable you to update alert content and recipients dynamically, which provides much more flexibility. Let’s say you already know that certain scheduled maintenance tasks will affect particular resources. In that case, you could create a policy to disable notifications for those alerts. Another example: a while ago, we managed customer instances for a certain period of time in order to cover a PoC. We created a special policy that allowed us to manage such instances without having it affect the way we manage production instances.
Incidents
Incidents are specific, high-priority alerts – either because they signify a critical event or because they cause service interruptions. Whenever incidents occur, you will want to keep stakeholders notified every step of the way. Once the incident has been resolved, you will have a wealth of relevant information and communications to create a knowledge base. One cool feature of Opsgenie’s incident management tool is that it enables users to start a video conference with all responders and stakeholders directly from the incident alert.
Reporting
Because all alerts are centralized in Opsgenie, users can easily gain insight on the infrastructure’s general health. The tool comes with a central dashboard through which both the Dev and Ops teams can generate reports based on different metrics. For example, Opsgenie allows us to track incident response rates and incident age, as well as keep an eye on which services generate the most incident reports.
Opsgenie benefits for Valiantys
Ever since we started using Opsgenie as our centralized alert management system, dealing with alerts from the hundreds of customer instances we’re involved in has become much easier – and much less stressful. On top of that, maintenance tasks are much more streamlined and incident management is more transparent. Opsgenie comes with lots of handy built-in features, and while we’ve explained a number of those above, we still have much more to explore!
Inspired by our experience? You too can benefit from the Opsgenie features and improve your ITSM performance.
Tell me more


